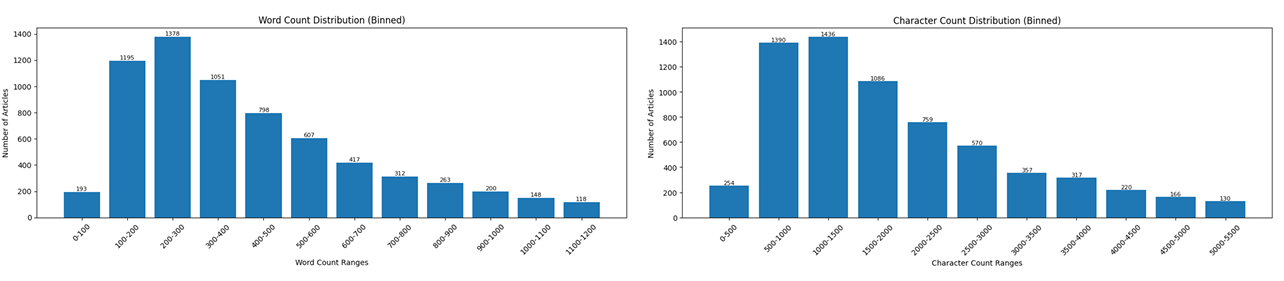
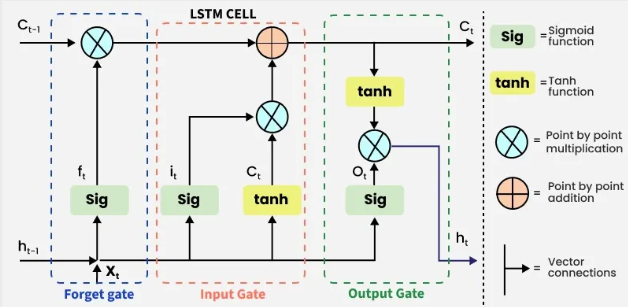
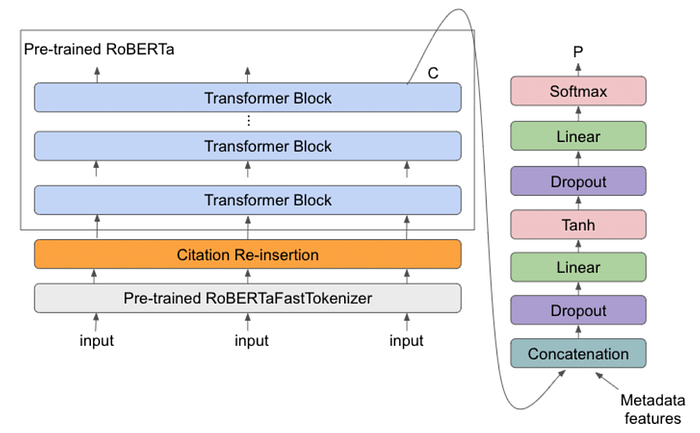
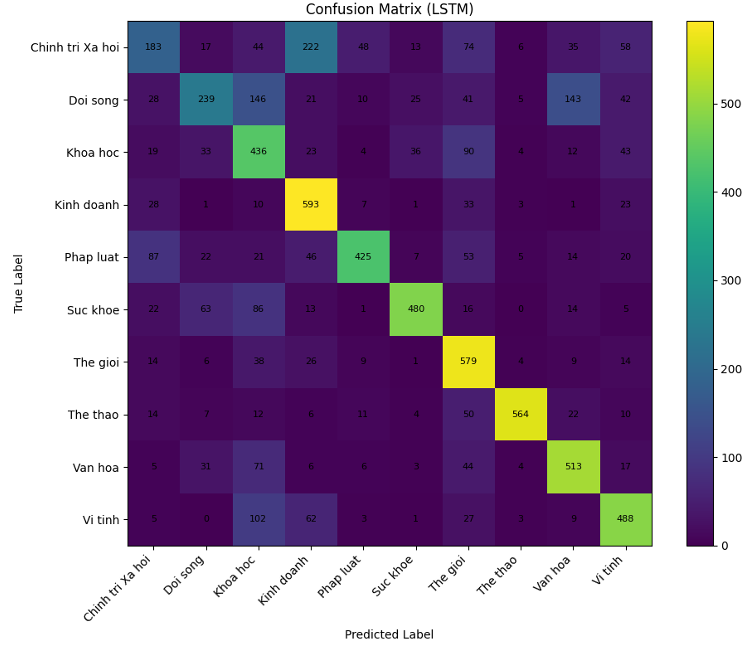
Common Confusions
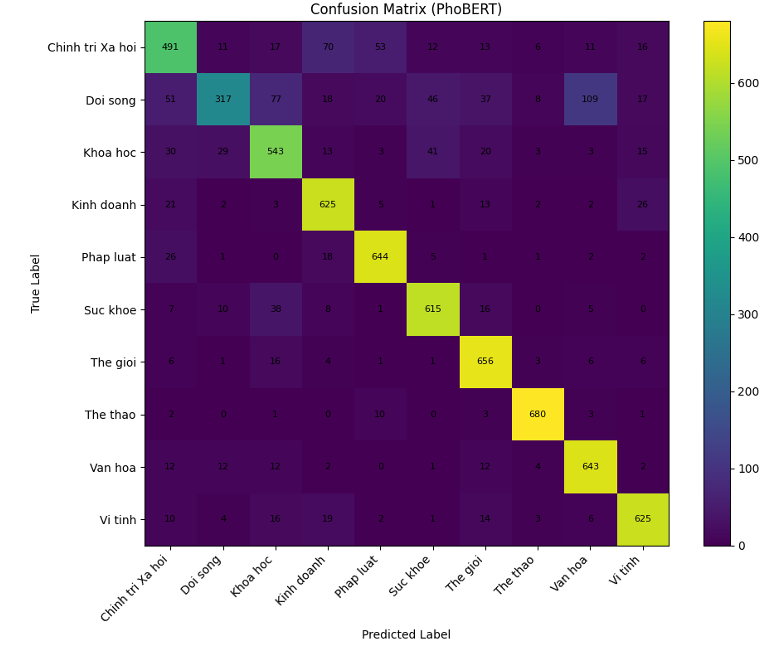
By analyzing the Confusion Matrices above, we noticed both models struggle with multi-topic or ambiguous articles where semantic overlap exists. Here are the most frequent misclassifications:
- LSTM: Chính trị Xã hội ➔ Kinh doanh (222 errors)
- LSTM: Đời sống ➔ Khoa học / Văn hóa
- PhoBERT: Đời sống ➔ Văn hóa (109 errors)
- PhoBERT: Chính trị Xã hội ➔ Pháp luật
Real-world Error Examples
"Uỷ ban thuyết phục HĐND TP HCM cho tăng giá nước..."
TRUE: Chính trị Xã hội
LSTM PRED: Kinh doanh
"Ngân hàng Chính sách xã hội thiếu vốn cho vay..."
TRUE: Chính trị Xã hội
PhoBERT PRED: Kinh doanh
"Trại hè tiếng Anh Apollo sẽ diễn ra tại khu du lịch..."
TRUE: Chính trị Xã hội
LSTM PRED: Văn hóa
📌 Insight on Errors: Articles discussing "prices" (giá nước) or "loans" (vốn cho vay) heavily skew the models towards the Kinh doanh (Business) class, despite the core subject being government policy. This highlights the challenge of classifying text based on overlapping vocabulary rather than deep contextual intent.